

阿里云
阿里云——阿里巴巴集团旗下全球领先的云计算及人工智能科技公司之一。提供全栈云服务,包括弹性计算、高性能数据库、网络与存储方案,以及AI大模型、向量检索、大数据分析等智能化能力。依托飞天云计算操作系统与全球基础设施,支持企业构建高可用架构,定制基于场景的行业解决方案,免费备案,7×24小时售后支持,助企业无忧上云。
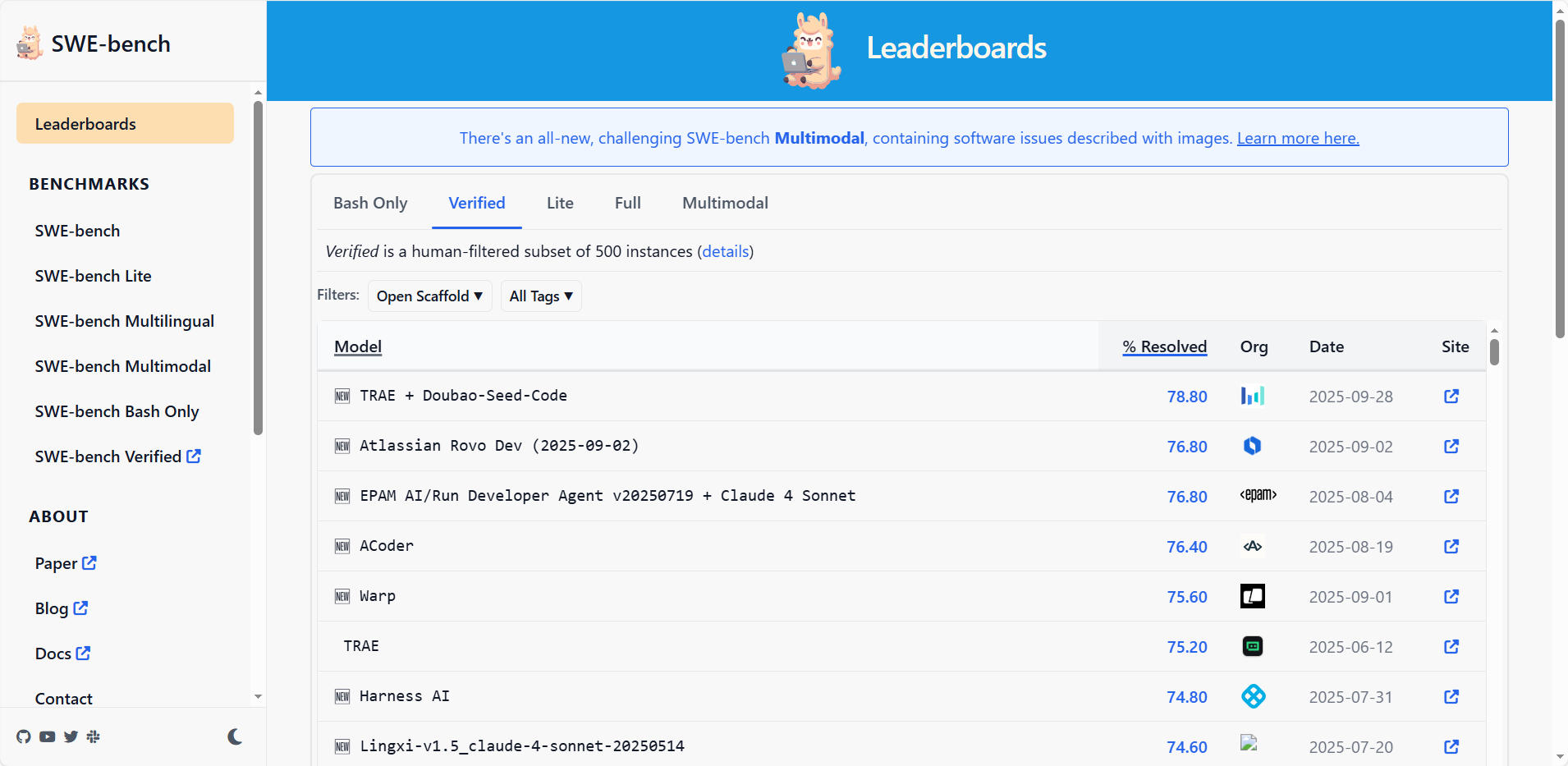
SWE-bench 是评估大型语言模型(LLM)在软件工程环境中完成现实世界任务能力的核心 AI 评估基准。该基准包含 500 个独立任务,每个任务部署于专属 Docker 容器,均源自 GitHub 真实代码库问题;模型将配备智能体工具,需生成 “补丁” 解决对应问题,其解决方案的成功与否,由运行单元测试的结果直接判定。
SWE-bench网站提供全球流行的大语言模型排行榜,排行榜的依据为GitHub问题的解决率。截止本文发布时间,目前排名第一的是字节跳动旗下的TRAE + Doubao-Seed-Code,解决了 500 个问题中的 78.80%。
SWE-Bench 主要来自知名学术机构的研究人员合作开发,具体由 Carlos E. Jimenez 等人(含普林斯顿大学学者)与斯坦福大学 John Yang 共同提出,Alexander Wettig、Shunyu Yao、Kexin Pei、Ofir Press 及 Karthik Narasimhan 亦参与贡献。




